Módulo 1.1 — Introdução ao Microsoft Fabric
Ao final deste módulo, você será capaz de compreender a arquitetura unificada do Microsoft Fabric, identificar quando utilizar cada experiência da plataforma, e navegar com fluência pelo ambiente de trabalho que utilizamos na Química Anastacio.
Por que Microsoft Fabric na Anastacio?
Antes de mergulharmos nos conceitos técnicos, é importante entender o contexto da nossa escolha pelo Microsoft Fabric. A Química Anastacio opera com o ecossistema da Microsoft e tambem com o TOTVS Protheus como sistema ERP central, gerando um volume significativo de dados transacionais que precisam ser transformados em informação analítica. Historicamente, esse processo envolvia múltiplas ferramentas desconectadas: extrações manuais, planilhas Excel intermediárias, e relatórios Power BI que consumiam dados de fontes dispersas.
O Fabric representa uma mudança de paradigma porque unifica todo o ciclo de vida dos dados em uma única plataforma. Isso significa que a extração dos dados do Protheus, a transformação em camadas Bronze, Silver e Gold, a modelagem dimensional, e a visualização em dashboards acontecem dentro do mesmo ecossistema, com governança centralizada e linhagem de dados rastreável de ponta a ponta.
O que é Microsoft Fabric
O Microsoft Fabric é uma plataforma de analytics unificada que combina tecnologias de ingestão, engenharia, ciência de dados, data warehouse, análise em tempo real e business intelligence em um único produto SaaS. Lançado em 2023, o Fabric representa a evolução e consolidação de diversas ferramentas que a Microsoft oferecia separadamente, como Azure Synapse Analytics, Azure Data Factory e Power BI Premium.
A palavra-chave aqui é "unificada". Diferentemente de arquiteturas onde você precisa provisionar e conectar múltiplos serviços (um serviço para ingestão, outro para transformação, outro para armazenamento, outro para visualização), o Fabric oferece todas essas capacidades de forma integrada, compartilhando uma camada de armazenamento comum e um modelo de segurança único.
Para quem já trabalha com Power BI, o Fabric pode ser entendido como uma expansão massiva das capacidades da plataforma. O Power BI que você conhece continua existindo dentro do Fabric, mas agora acompanhado de ferramentas de engenharia de dados que antes exigiam conhecimento de Azure e infraestrutura de nuvem.
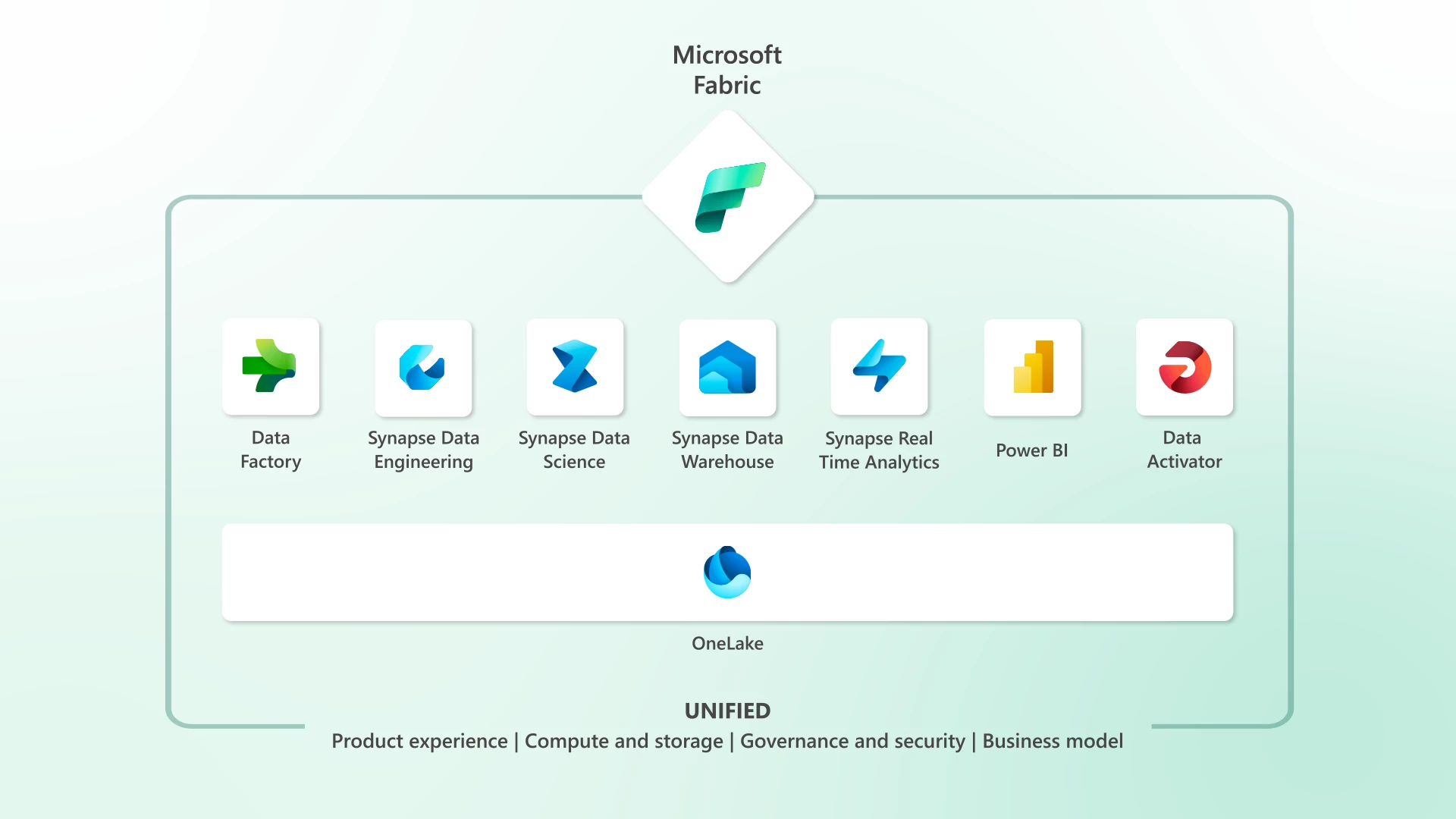
A Arquitetura Unificada do Fabric
O Fabric é construído sobre três pilares fundamentais que você precisa compreender para trabalhar efetivamente com a plataforma.
Primeiro Pilar: OneLake
O OneLake é a camada de armazenamento unificada do Fabric. Pense nele como o "OneDrive dos dados corporativos". Assim como o OneDrive oferece um único local para armazenar seus arquivos pessoais independentemente de qual aplicativo você usa para criá-los, o OneLake oferece um único local para armazenar todos os dados analíticos da organização, independentemente de qual ferramenta do Fabric você usa para processá-los.
Tecnicamente, o OneLake é construído sobre o Azure Data Lake Storage Gen2, utilizando o formato Delta Lake como padrão para tabelas. Isso traz benefícios importantes:
- Transações ACID — garantindo consistência dos dados mesmo em operações concorrentes
- Versionamento automático — permitindo "time travel" para versões anteriores dos dados
- Otimização automática — compactação e organização de arquivos sem intervenção manual
Na prática, isso significa que quando você cria uma tabela em um Notebook usando Spark, essa mesma tabela fica imediatamente disponível para consulta via SQL no endpoint analítico, e pode ser consumida diretamente pelo Power BI sem necessidade de importação. Os dados existem em um único lugar e são acessados por múltiplas ferramentas.
Segundo Pilar: Experiências e Cargas de Trabalho
O Fabric organiza suas ferramentas em "experiências", cada uma otimizada para um perfil de usuário e tipo de tarefa específico. Você alterna entre experiências usando o seletor no canto inferior esquerdo da interface.
| Experiência | Objetivo | Aplicação na Anastácio |
|---|---|---|
Data Factory | Automatizar a movimentação e transformação de dados através de pipelines visuais e Dataflows Gen2 | Pipelines de extração diária do Protheus (tabelas SA1, SA2, SD1, SD2, SB1) para a camada Bronze. |
Data Engineering | Criar Lakehouses, desenvolver notebooks PySpark e executar transformações em larga escala | Notebooks de transformação Bronze → Silver → Gold, tratamento de qualidade e criação de dimensões. |
Power BI | Criar relatórios, dashboards e modelos semânticos para análise de negócio | Dashboards de vendas, estoque, financeiro e operacional consumindo dados da camada Gold via Direct Lake. |
Data Science | Treinar modelos de machine learning, gerenciar experimentos com MLflow e fazer deploy de modelos | Modelo de previsão de churn de clientes, análise preditiva de demanda. |
Data Warehouse | Armazenar e consultar dados usando T-SQL em um ambiente gerenciado | Consultas ad-hoc para áreas de negócio que preferem SQL, views para integrações específicas. |
Durante esta trilha, você trabalhará principalmente com Data Factory (ingestão), Data Engineering (transformações) e Power BI (visualização). Essas três experiências compõem o fluxo completo que utilizamos na Anastácio para levar os dados do Protheus até os dashboards de negócio. As demais experiências serão apresentadas conceitualmente, e o módulo extra de Machine Learning aprofundará a experiência de Data Science.
Terceiro Pilar: Capacidades
Uma Capacidade (Capacity) no Fabric é a unidade de computação que alimenta todas as operações. Pense na capacidade como o "motor" que executa suas cargas de trabalho. Quando você executa um notebook, roda um pipeline, ou atualiza um relatório, está consumindo recursos da capacidade.
As capacidades são dimensionadas em SKUs que vão de F2 (a menor) até F2048 (a maior). O número representa a quantidade de Capacity Units (CUs) disponíveis. Uma F64, por exemplo, oferece 64 CUs de poder computacional.
A Química Anastácio utiliza uma capacidade F16, que oferece 16 CUs de poder computacional. Esta capacidade atende às necessidades atuais de processamento e pode ser escalada conforme o crescimento do volume de dados.
A capacidade é compartilhada entre todos os workspaces atribuídos a ela. Cargas de trabalho pesadas em um workspace podem impactar a performance de outros workspaces na mesma capacidade.
Modelo de Licenciamento
O licenciamento do Fabric pode parecer complexo inicialmente, mas segue uma lógica consistente que vale a pena entender.
Licenças de Usuário
No nível de usuário, existem dois tipos de licença relevantes:
| Licença | Permissões |
|---|---|
| Pro | Criar e publicar conteúdo em workspaces atribuídos a capacidades Fabric |
| Gratuita (Free) | Apenas consumir conteúdo, não criar |
Todos na área de TD da Anastacio possuem licença Pro.
Licenças Pro para outras áreas, podem ser concedidas mediante análise de necessidade. Para mais informações contatem o time de TD.